

As a provider of incident management software, we at incident.io handle sensitive data related to our customers, including Personally Identifiable Information (PII) about their employees and confidential details about customer incidents. This data is managed with great care, and this blog post will outline our practices for handling sensitive data within our data warehouse, BigQuery. We will also provide a deeper technical implementation for our more technically inclined audience.
Before we dive into the topic, here’s a quick diagram illustrating our workflow:
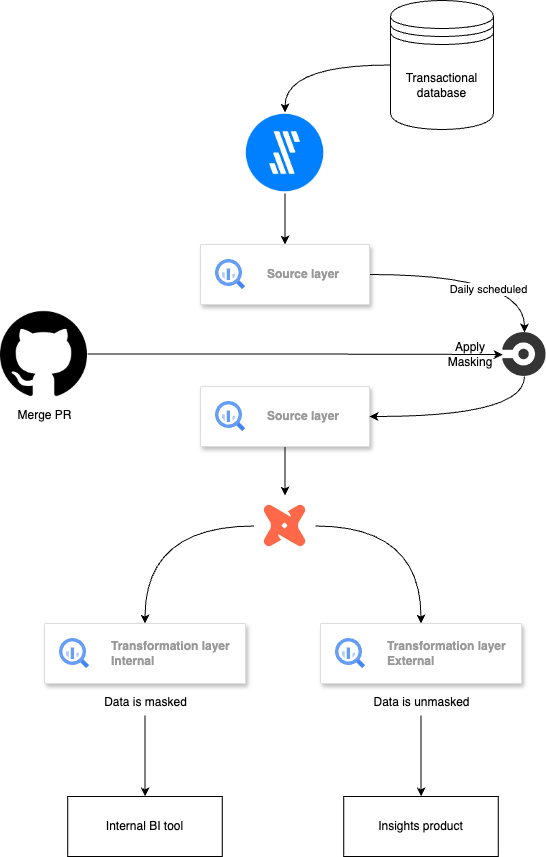
For context, we use Fivetran to replicate our transactional database into BigQuery, dbt for data transformations, and CircleCI to manage all orchestration processes.
How do we detect sensitive data?
Default masking in the source layer
By default, all new columns from our transactional database are marked as sensitive in BigQuery. Users without the appropriate permissions can only view the data in a masked format. An example of how incident names and summaries appear when queried without permissions is shown below:
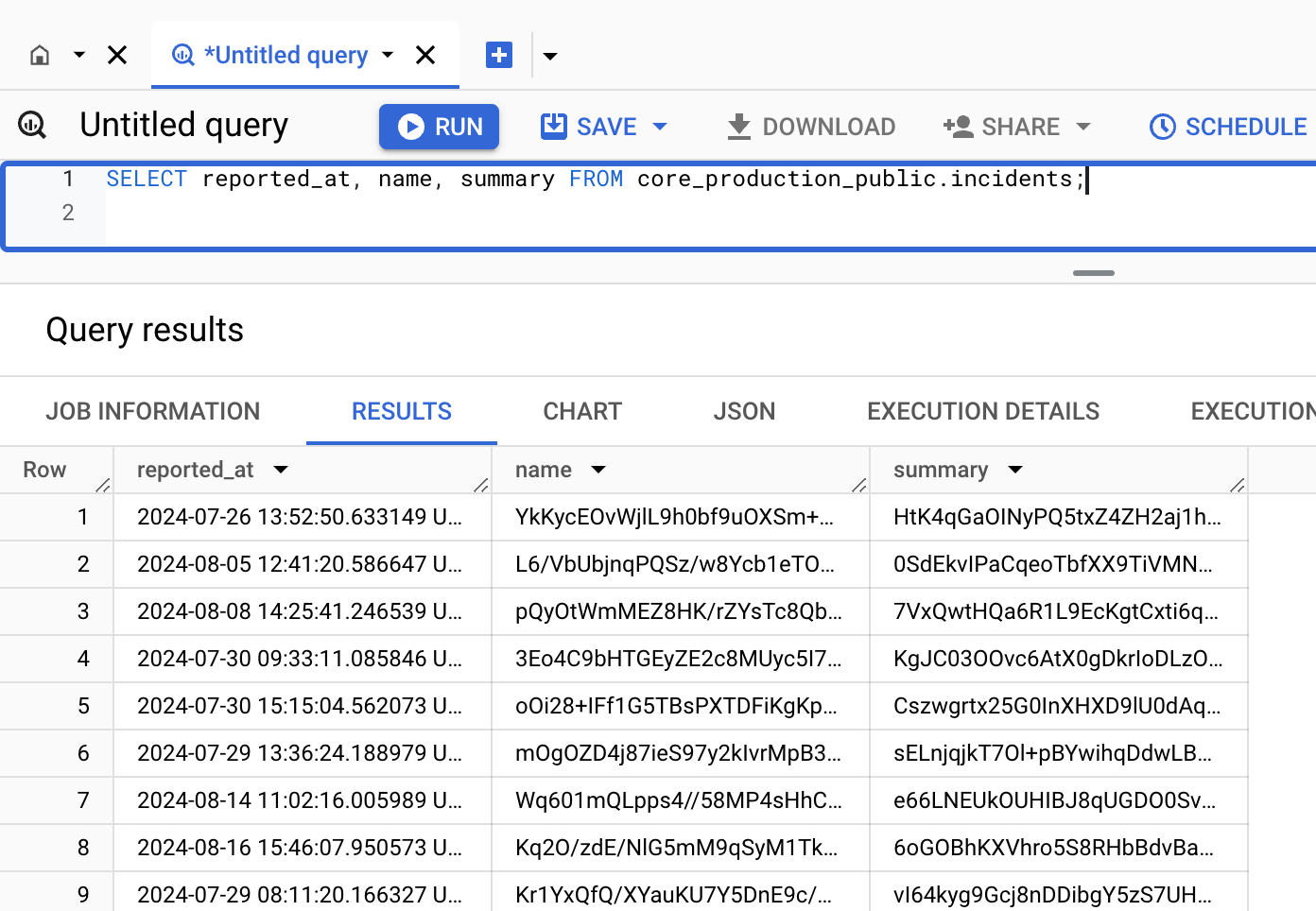
Currently, only our customer-facing dbt service account can view this data in an unmasked format.
This workflow involves several key components:
- Establishing a taxonomy and creating policy tags for PII and confidential information
- Implementing a scheduled daily job in Python to scan all tables in our transactional database within BigQuery and apply policy tags to untagged columns
- Restricting human users within the company to access columns with applied policy tags in a masked format
Masking in dbt
Most of our columns do not contain sensitive data, so masking them by default leads to false positives. To remove policy tagging from a column, we have created YAML files in our data repository that list non-sensitive columns. The process to untag a column involves submitting a PR to add the column name to the relevant YAML file(s) and merging the PR to activate the daily workflow.
How is sensitive data handled downstream?
We use dbt for data transformations and have separated our dbt pipeline into customer-facing and internal analytics streams. The customer-facing pipeline allows full access to sensitive information in a non-masked format for our customers, while the internal analytics pipeline manages sensitive data in a masked format for internal use.
When refreshing dbt models, masked data is pulled from the source and hardcoded into downstream tables, reducing the likelihood of human errors. Limitations include challenges in transforming sensitive data into non-sensitive formats.
How does the workflow work under the hood?
Our policy tag workflow comprises two functions, with the first function parsing the input YAML file into a readable format for the second function.
def column_list_to_dict(column_yml_file_dir: str, column_yml_file_name: str, is_slim_run: bool = False, slim_run_artifacts_location: str = ".") -> Dict[str, Dict[str, Dict[str, List[str]]]:
"""Takes a yml file of columns and returns dictionary
Args:
column_yml_file_dir (str): Dir to yml file.
column_yml_file_name (str): yml file name.
is_slim_run (boolean, optional): If this is a slim run (i.e. deployment). Defaults to false.
slim_run_artifacts_location (str, optional).
exclude_columns (Dict[str, Dict[str, Dict[str, List[str]]]): Nested dictionary of columns to exclude.
is_slim_run (bool): Flag to indicate if it is a slim run.
slim_ci_columns (Dict[str, Dict[str, Dict[str, List[str]]]): Nested dictionary of columns for slim CI.
Returns:
List[str]: List of columns to which the policy tag was successfully applied.
“””
columns_to_apply_policy_tag = []
dataset_columns = get_dataset_columns(project_id, dataset_id)
for table_name, columns in dataset_columns.items():
for column_name in columns:
if column_name not in exclude_columns.get(project_id, {}).get(dataset_id, {}).get(table_name, []):
if is_slim_run:
if column_name in slim_ci_columns.get(project_id, {}).get(dataset_id, {}).get(table_name, []):
columns_to_apply_policy_tag.append(column_name)
else:
columns_to_apply_policy_tag.append(column_name)
apply_policy_tag_to_columns(project_id, dataset_id, columns_to_apply_policy_tag, policy_tag, classification)
return columns_to_apply_policy_tag
This function applies a policy tag to all columns in a dataset unless they are specified in the exclude_columns parameter. The policy tag is applied based on the classification provided. The function iterates through the columns in the dataset, checks if they are excluded based on the exclude_columns dictionary, and then applies the policy tag if the column is not excluded. The function also considers the is_slim_run flag to determine whether to apply the policy tag based on the slim_ci_columns dictionary.
Either personally identifiable information (PII) or confidential information.
exclude_columns (Dict[str, Dict[str, Dict[str, List[str]]]]): Dictionary of columns to be excluded from the tagging policy.
is_slim_run (boolean, optional): Indicates if this is a slim run (i.e. deployment). Defaults to false.
slim_ci_columns (nested_dict, optional): A list of columns from which the policy tag should be removed. sentence: “The cat chased the mouse around the house.”
Rewritten sentence: “Around the house, the mouse was chased by the cat.”

