

PDF files are supported in Intezer for both on-demand sandboxing and automated alert triage, as well as all other file types commonly used for delivering malware, like binary files or Microsoft Office formats.
Portable Document Format (PDF) files are a cross-platform file format that supports links, images, and fonts. The flexibility of the PDF format makes these files very useful and widely used by individuals and organizations all over the world. At the same time, this format is very appealing for cyber criminals, as they can create valid-looking PDF documents that will deliver malicious code or trick users into clicking links. A 2023 report found PDFs were the most commonly attached malicious file type for phishing emails.
Many attacks start from a received file, usually attached to a phishing email. Then once the victim opens the file or interacts with it by clicking on links or buttons, the next stage of the attack is executed. The purpose of the attack can be information stealing, installing a backdoor, gaining access to the system, and more.
One of the challenges of incident responders is to identify and classify the malicious files that were used in the attack that compromised the endpoint. PDF files make the process more time-consuming because PDF files can carry malicious code that is hidden and compressed inside the streams of the file, all while these files are widely used for legitimate business both internally and externally in organizations. On top of that, alert fatigue can be a cause of missed alerts and increase the response time of new files to analyze.
In this article, we will describe the PDF format and how it can be abused to deliver malware. Then we will show how you can identify and detect a malicious PDF file using open-source and free tools. At the end, we’ll look at how you can automatically collect and analyze PDFs for ongoing alert triage.
What is the PDF File Format?
The PDF format was created by Adobe in 1993 as a text-based structure that gives users a reliable way to present documents regardless of the operating system and the software they are using. Besides text, PDF files can present a wide variety of content such as images, links, video files, 3D objects, editable forms, and much more. Many products include features to download or “save as PDF,” allowing users to edit the content in another format (like Microsoft Office files) before creating the PDF.
The PDF structure is hierarchical and contains four main parts:
1. Header – Specifies the version number of the PDF.
2. The body – The document’s part that holds all of the information including text and other elements such as images, links, etc.
The body of the PDF file contains different objects that can reference each other; the objects have different types:
- Names – /name backslash followed by ASCII characters – setting a unique name.
- Strings – (text) its full syntax is a bit complex but what’s important is to know that it is enclosed in parentheses.
- Arrays – enclosed with square brackets ([…]) can contain other objects.
- Dictionaries – table of key and value pairs. The key is a name object and the value can be any other object. Enclosed within double angle brackets (<<…>>)
- Streams – contains embedded data structures like images (or code) which can be compressed. Streams are represented by a dictionary that sets the stream’s length with the key /Length and encoding /Filters.
- Indirect object – object that has a unique ID, the object starts with the keyword obj and ends with endobj. Other objects can reference the object using its ID. For example, a reference to an object with ID 3 would look like this: 3 0 R
3. Cross-reference table – Specifies the offset from the start of the file to each object in the file so that the PDF reader will be able to locate them without loading the whole document (it can save time when opening big files).
4. Trailer – Specifies information about the cross-reference table so the PDF reader will be able to find the table and other objects. PDF readers start reading the file from the end, let’s look at the example below:
xref
0 14
0000000000 65535 f
0000000015 00000 n
0000000660 00000 n
0000000803 00000 n
0000001007 00000 n
0000001322 00000 n
0000001049 00000 n
0000001410 00000 n
0000001200 00000 n
0000001461 00000 n
0000001513 00000 n
0000001573 00000 n
0000001632 00000 n
0000001737 00000 n
trailer
<</Size 14/Root 12 0 R/Info 13 0 R/ID [<019e8b45c3227a3f8f35b7a9a09c2f70><019e8b45c3227a3f8f35b7a9a09c2f70>]>>
%iText-5.5.10
startxref
1901
%%EOFThe first line (from the bottom) is %%EOF above is the offset of the cross-reference table – 1901. Above that is the trailer that specifies different settings:
- Size – number of entries in the cross-reference table
- Root – which entry in the table holds the offset for the root object. This object is the Document Catalog; it contains information about how the file will be presented and references to other objects that describe the document’s content.
- Info – which entry in the table holds the offset for the document’s information dictionary.
PDF files can be modified so additional elements (such cross-reference tables) will be appended to the end of the file. Now that we understand the format, let’s see how it can be used by attackers to conceal malicious code.
Check out this video on our YouTube channel about analyzing PDFs, where I cover the information in this blog as well as four examples of malicious PDFs that were used in real attacks.
How PDF Files Get Used to Deliver Malware
PDF files support a wide variety of data types that can be present (and not necessarily visible). Threat actors fully control the content of the files they send to lure victims, and they use the different capabilities of the PDF format for their attacks.
Many phishing attacks will contain links, which may appear as clickable images of buttons, coupons, fake CAPTCHA, fake play buttons, or QR codes.
The embedded files in PDFs are used by threat actors to redirect victims to malicious sites controlled by them, enabling the next stage of the attack. PDF files can contain JavaScript that triggers scripts upon opening, leading to the download of additional payloads or theft of information.
Threat actors can also embed malware in PDF streams, which can include various types of data, such as scripts and binary files, often compressed and encoded to evade detection. Exploiting vulnerabilities in PDF readers like Adobe PDF Reader, which has a significant number of reported vulnerabilities, threat actors can execute code and gain access to victims’ endpoints.
For example, in a phishing scam targeting German-speaking victims, a malicious PDF file was attached to an email posing as a tax invoice, prompting victims to login to their Amazon account. The PDF file, when analyzed with tools like peepdf and pdf-parser, revealed encoded JavaScript code that redirected victims to a fake Amazon login page for credential stealing.
In another example, a different malicious PDF file contained an embedded file with Rich Text Format data, uncovered through analysis with peepdf and pdf-parser. This demonstrates the various ways threat actors use embedded files in PDFs to conduct malicious activities and exploit vulnerabilities in PDF readers. To examine the file, we will utilize rtfobj from oletools:

In a previous blog post discussing the analysis of malicious Office files, more details on tools and techniques for files like RTF can be found. The rtfobj output reveals that the extracted RTF file exploited CVE-2017-11882, a known vulnerability in Microsoft Equation Editor that allows for code execution. Microsoft has since patched this vulnerability, rendering this attack effective only if the user neglects to update their software. Moving forward, we have the option to delve deeper into the shellcode within the RTF file or upload the original PDF to Intezer for an automated analysis and threat classification.
The analysis results are displayed in the following screenshot:
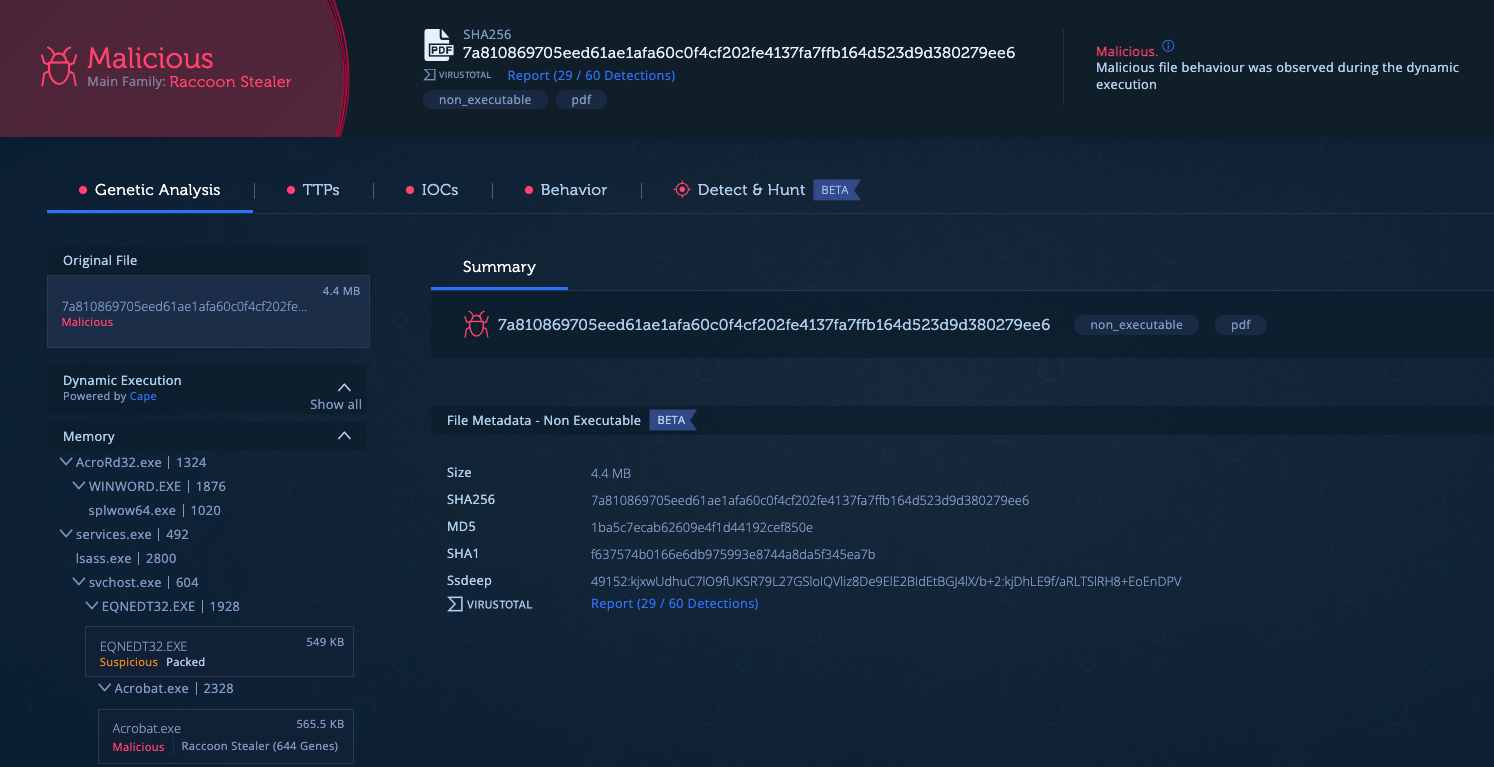
In the process tree, we observe the sequence of events from the PDF’s execution to the opening of the RTF file in Word, followed by the exploitation of Equation Editor by the RTF. The malware is identified as Raccoon Stealer. The Genetic Analysis section indicates that the sample shares code with Azorult, as Raccoon Stealer is considered its successor.
### Scanning a High Volume of PDFs for Malware
PDF files are prevalent and beneficial for various organizations, but their versatile format also makes them a prime target for threat actors seeking to execute different attacks. This blog highlighted several open-source and free tools for static analysis of individual PDF files.
However, manual analysis of PDFs becomes impractical for organizations dealing with a large number of files that require investigation. In such cases, leveraging a platform like Intezer can automate the initial file assessment, allowing teams to focus efforts on cases necessitating manual analysis.
Analyze files, including PDFs, for free with Intezer. To explore how your team can automate alert triage for scanning files, URLs, memory dumps, and more, schedule a discussion with us.
*Author: Nicole Fishbein*
Nicole, a malware analyst and reverse engineer, previously served as an embedded researcher in the Israel Defense Forces (IDF) Intelligence Corps.
**Previous Post:** [Introducing AI Insights for Processes: Triaging Command Lines and Other Text-Based Evidence](https://intezer.com/blog/incident-response/ai-insights-for-processes-command-lines/)
**Next Post:** [Detect Phishing Emails by Inspecting Email Headers, Attachments, and URLs](https://intezer.com/blog/incident-response/automate-analysis-phishing-email-files/) following sentence in a more concise way:
“Despite the fact that it was raining heavily, we still decided to go for a walk in the park.”
“We still decided to go for a walk in the park despite the heavy rain.”


