

Hey there! I’ve been in quite a few jobs, and in each one, I’ve stumbled upon a new observability tool that becomes indispensable. It’s like a superpower for us at incident.io – we catch bugs quicker than our customers can even report them!
A while back, I was all about Prometheus. Then, in my last gig, it was all about holding onto our logs for a month and using the Elastic stack (back then, it was known as the ELK stack: Elasticsearch, Logstash, and Kibana).
But here at incident.io, traces stole the show. They’ve been a game-changer in debugging our systems, especially during local troubleshooting. Today, I want to dive into the world of browsing and querying traces and spans, and give you a peek into how we implement them in our codebase.
If you’re curious, Martha penned down a brilliant piece on our observability strategy, delving deep into how we handle observability at incident.io.
What exactly is a trace?
Think of a trace as the journey a request makes through your application. It’s not just limited to HTTP calls to an API – it could be any task, like a scheduled job or event consumption.
A trace is essentially a collection of spans, with each span representing a specific task. There’s a root span, and every other span has a parent. While details may vary, spans typically have an ID, a name, attributes, and start and end times. Crucially, child spans are linked back to their parent span via IDs.
We’re big fans of OpenTelemetry here, so I’ll focus on that in this post. However, the principles should apply to any tracing format or library you use.
Why should you care about traces?
Let’s take an example of an HTTP request to our /incidents/:id API. The request comes in, undergoes various operations like authentication and database lookup, and finally, a response is generated.
Each of these operations translates into a span. By visualizing these spans in a tree-like structure, you get a detailed picture of the sequence of events, allowing you to:
- Track the order and duration of each operation.
- Spot bottlenecks or slow processes easily.
- Identify inefficiencies like redundant queries or data duplication across the codebase.
Delving into spans
Names play a crucial role here, as most tools display them prominently in the trace overview. It’s beneficial to follow a naming convention that’s familiar to everyone – for instance, including the table name in database query spans and using a package.FunctionName format for other calls.
Span metadata is a goldmine of information. Here are a few examples:
- Our “HTTP” span always includes the request path, response code, and referrer, providing insights into the request source.
- Database query spans contain attributes like the queried table, rows affected, and a query fingerprint, aiding in identifying performance issues.
- HTTP client spans detail outbound requests, response data, and can be marked as failed for error scenarios.
Let’s get technical: how does it look in code?
In our codebase, we get a lot of spans automatically, which is a huge plus. But what if we need to add custom spans from within our code?
Consider a scenario where we have a strict time limit to handle Slack interactions. Speed is crucial, but so is the ability to troubleshoot any slowdowns effectively.
Let’s envision a function that manages Slack interactions:
func (svc *Service) HandleInteraction(ctx context.Context, cb slack.InteractionCallback) error {
ctx, span := md.StartSpan(ctx, md.SpanName(), md.Metadata{
"callback_type": cb.Type,
})
defer span.End()
if _, err := svc.handleInteraction(ctx, cb); err != nil {
md.SpanRecordError(span, err)
return err
}
return nil
}This snippet showcases our internal md library, utilized for both tracing and logging. It kicks off a span, assigns attributes like callback type, names the span based on the function, and ensures the span is closed properly even in error scenarios.
Taking it up a notch
To streamline error handling and span closure further, you can leverage defer with named return parameters. Check out this example:
func HandleAlert(ctx context.Context, alert *domain.Alert) (err error) {
ctx, span := md.StartSpan(ctx, md.SpanName(), md.Metadata{
"alert": alert.ID,
})
defer func() {
if err != nil {
md.SpanRecordError(span, err)
}
span.End()
}()
}By using this pattern, you streamline error handling and span closure, making your code more efficient. This approach can be extended to setting other attributes and is handy for recording values in Prometheus histograms as well.
Now, let’s shift our focus to where these spans end up. For local development, each of us has a Google Cloud Platform project, with traces landing in Cloud Trace. This setup proves invaluable during local debugging, especially when trace URLs are displayed alongside log lines:
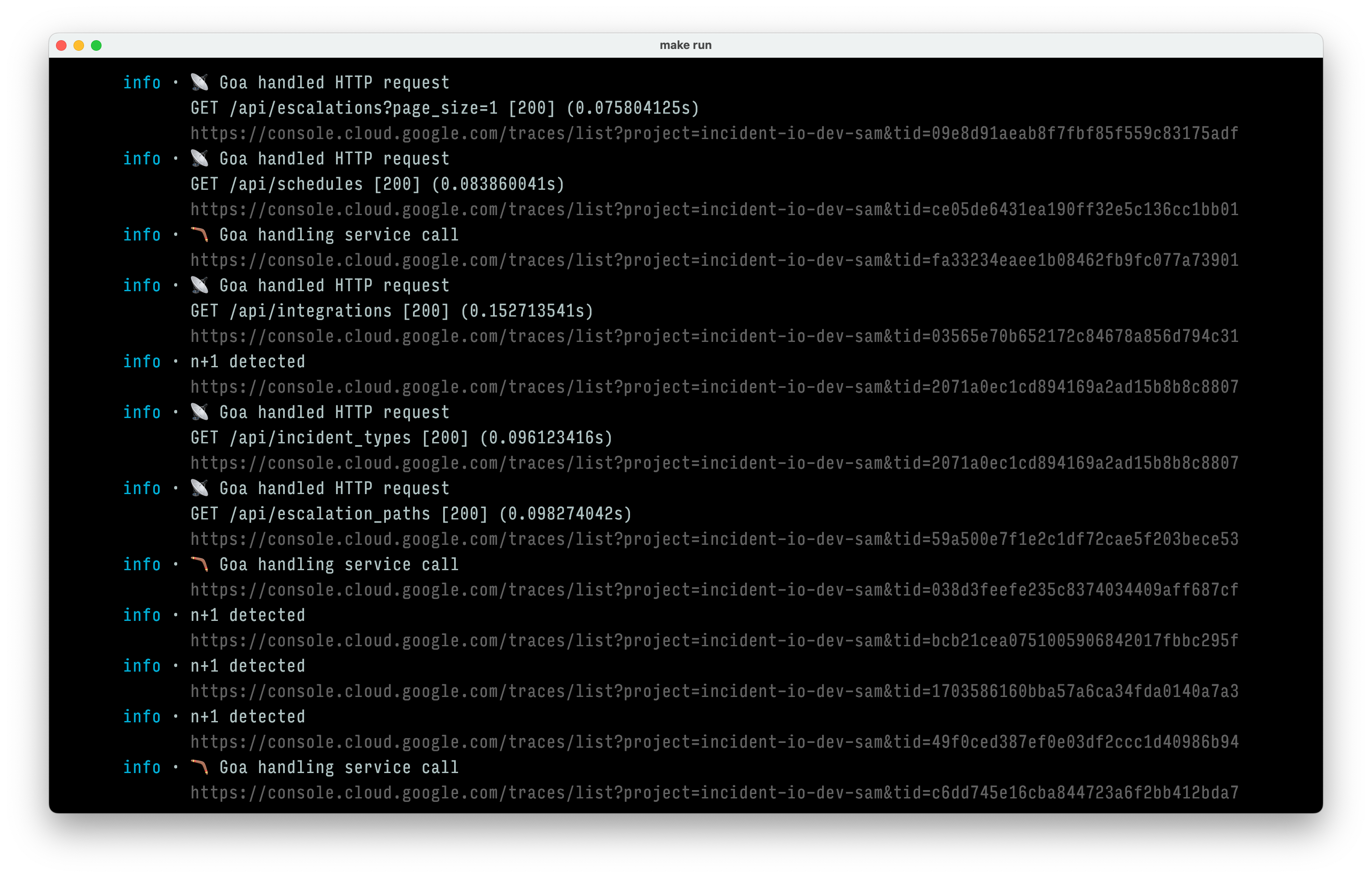
In production, our traces find their way to Grafana using Tempo. Both Grafana and Google Trace offer robust querying capabilities, but we’ve found Grafana’s TraceQL to be more versatile and expressive.
We tag many of our spans with user or organization IDs, allowing me to:
- Retrieve all traces involving queries to the incidents table for a specific organization.
- Track the trace related to handling a particular alert ID.
- List all traces for the “list incidents” API endpoint that took more than two seconds to process.
Having these traces accessible via a web interface enables easy sharing among engineers during incident responses. Almost every incident discussion includes a “Hey, check out this suspicious trace” moment.
Once an engineer at incident.io latches onto a trace, they’re usually just a step away from pinpointing the issue precisely, setting the stage for a swift bug fix.
Why is it a superpower?
Tracing offers a deep dive into our system’s behavior with unparalleled detail. We’ve seamlessly integrated it with our logging and error reporting processes – every log includes a trace_url attribute, and Sentry alerts (our go-to error handler) come with trace URLs too.
So, when the alert bells ring, we simply hop into Sentry, follow the trace link, and get a crystal-clear picture of what unfolded.
Key tips to keep in mind
If you’re considering implementing or enhancing your tracing setup, here are some pointers:
- Strive to have spans generated automatically wherever possible. In our case, starting spans for database and HTTP clients yields rich insights right off the bat.
- Ensure the traces are stored in a query-friendly location, and educate your team on basic querying techniques.
- Make the traces highly accessible: embed them in log metadata, error messages, HTTP headers (we include a trace ID in each response), and anywhere they could offer value.
- Align your local environment with production as closely as you can. Having tracing available locally helps everyone hone their tracing skills, fostering a proactive attitude towards leveraging traces.
Of course, there are some pitfalls to avoid too. Understand the cost implications of storing large volumes of traces and the impact of excessive spans (and attributes) on those costs. Keep in mind that attribute names and values often come with restrictions.
How do you leverage tracing?
Tracing is a versatile tool, and our approach is just one way to harness its power. While we operate as a monolith, tracing is equally beneficial in distributed architectures. How do you tackle tracing in your setup? What unique insights can you share? We’re all ears!


